Using GPT-4 Until I Hit The "Inevitable" Wall

Have tinkered with JavaScript majorly | I like to solve problems on Stack Overflow, write blog articles, create a side project or do something creative.
In this article, I am going to be elaborating on how I used GPT-4 to write python code to detect Dysarthria speech and output the transcribed words. But basically, I couldn't get it to work due to a lack of domain knowledge.
Introduction
Back in 2017-2018 during my college years, I worked on a project with my friend about improving the intelligibility of dysarthric speech. Let's define some of this jargon for you:-
Dysarthria - It is a motor speech disorder that affects the ability of an individual to articulate words properly due to weakness or poor coordination of the muscles used for speech. It can be caused by various medical conditions, such as neurological disorders, brain injury, or degenerative diseases.
Intelligibility - Intelligibility refers to the degree to which speech can be understood by others. In the context of dysarthria, it refers to the degree to which individuals with dysarthria can convey their intended message through speech.
So all in all, we wanted a means to improve the understanding of words spoken by dysarthric people. At that time, Data Science & ML were very interesting things to me even though I lacked domain knowledge. We tried solving it through the means using some RNNs and stuff like that but I will be honest, we couldn't even get close. The reason was simple. We lacked domain knowledge. We didn't have the mentorship of a domain expertise person. All we did was google stuff, trying to play with hyperparameters around the data we gathered, cleaned and prepared for training.
So we abandoned the whole ML approach and couldn't proceed further on it.

At that time, I was all into python code. I knew python the best as far as I can remember. This is not true anymore. I have been writing JS professionally now for almost 3.5 years.
But now we have LLMs filling in the lines of code for us in languages we might be less aware of.
With the per-day advancement that's been going on, I wanted to revisit the college project from a different angle this time. Instead of trying to improve intelligibility, I wanted to know if we can build a POC ASR (Automatic Speech Recognition) tool for dysarthric people to transcribe the words spoken.
I told this same problem statement to GPT-4 and it did spin up some python code for me. Again, I still lack the domain knowledge of the whole ML space but I still wanted to give this a try to see where I will hit the wall finally.

In this article, I am going to utilize Hashnode's AI tools to summarise and explain the code that was written by GPT-4. It's only legit if an AI explains the work of another AI. Think of me as an instructor while the code and explanation are being done by the AI toolset.
The Dataset
It goes without saying but data is of the utmost importance when it comes to trying to build a corpus to train on any model.
I have the data obtained from UASpeech Database. This consisted of audio recordings of basically two types of speakers:-
Dysarthric: The speakers are categorized as F02, F03 (for female speakers), and M02, M03 (for male speakers), with each index representing a unique speaker.
Control: The speakers are categorized as CF02 and CF03 for females and CM02 and CM03 for males, respectively.
So, to figure out what's going on with dysarthria, scientists have recorded a bunch of audio of people with it talking. But, to make sure they're getting accurate results, they need a control audio too.
This allows for a comparison between dysarthric speech and normal speech, helping scientists identify the specific areas of speech that are affected by dysarthria.
For each dysarthric audio, there is a corresponding control audio. For example, if a dysarthric individual speaks the word "Command" in a labelled file named F02_B1_C12_M2.wav, then there is a corresponding control audio named CF02_B1_C12_M2.wav with the same utterance of "Command".
Hey, just a heads up - right now there aren't any written versions of these audio files. So basically, we can't see exactly what's being said. But we will get around it by generating the same via GPT-4's help.
Cleaning up the dysarthric audio
Our focus is on solving the challenge of understanding dysarthric audio. The issue lies in the prolonged duration of individual words and the presence of empty audio gaps. For now, we are not concerned with dialect or pronunciation. Furthermore, background noise amplifies the difficulty of predicting the intended word. To address these concerns, we tasked GPT-4 to provide us with Python code that performs noise reduction and voice activity detection.
import librosa
import numpy as np
import webrtcvad
import os
import torch
import torchaudio
import noisereduce as nr
def noise_reduction(waveform, sample_rate):
y = np.array(waveform)
y_reduced = nr.reduce_noise(y=y, sr=sample_rate)
return torch.Tensor(y_reduced)
def voice_activity_detection(waveform, sample_rate, vad_window=30):
vad = webrtcvad.Vad(3)
frame_duration = vad_window / 1000.0
frame_length = round(sample_rate * frame_duration)
num_frames = len(waveform) // frame_length
# Convert waveform to int16 and scale it
waveform_int16 = (waveform.numpy() * 32767).astype(np.int16)
active_frames = []
for i in range(num_frames):
frame = waveform_int16[i * frame_length : (i + 1) * frame_length]
is_speech = vad.is_speech(frame.tobytes(), sample_rate)
if is_speech:
active_frames.append(torch.tensor(frame, dtype=torch.float32) / 32767)
if len(active_frames) > 0:
return torch.cat(active_frames)
else:
print("No speech frames detected.")
return torch.tensor([], dtype=torch.float32)
def load_audio_librosa(file_path, sample_rate=16000):
waveform, _ = librosa.load(file_path, sr=sample_rate)
return torch.from_numpy(waveform), sample_rate
output_folder_vad = "/path/to/audio/files"
os.makedirs(output_folder_vad, exist_ok=True)
# load from Audio/F02
input_audio_files = librosa.util.find_files("/path/to/audio/files", ext=["wav"])
for input_audio_file in input_audio_files:
try:
waveform, sample_rate = load_audio_librosa(input_audio_file)
except:
print("Error loading file: {}".format(input_audio_file))
continue
# Apply noise reduction
waveform_denoised = noise_reduction(waveform, sample_rate)
# Apply voice activity detection
waveform_vad = voice_activity_detection(waveform_denoised, sample_rate)
# Save VAD processed audio if the tensor is not empty
if waveform_vad.numel() > 0:
output_vad = os.path.join(output_folder_vad, os.path.basename(input_audio_file))
torchaudio.save(output_vad, waveform_vad.float().unsqueeze(0), sample_rate)
else:
print(f"Skipping {input_audio_file} due to empty waveform after VAD.")
Explanation: The above code performs noise reduction and voice activity detection (VAD) on audio files. It uses the librosa library to load audio files in WAV format, applies noise reduction using the noisereduce library, and applies VAD using the webrtcvad library to detect speech segments in the audio. The active speech segments are then saved to a new file in the specified output folder if they are not empty. The VAD algorithm used here is based on the WebRTC implementation and the vad_window parameter specifies the time (in milliseconds) for each VAD window. The code also uses the torchaudio library to save the processed audio files.
Upon initial creation, the code did not meet expectations as the custom noise reduction logic produced subpar audio quality compared to my loaded audio. After 3-4 attempts of instructing GPT-4, I was able to generate the above code which provided improved audio quality surpassing my loaded audio. I thought the result was good enough for training.
Transcribing the control audio
As previously mentioned, each dysarthric audio has a corresponding control audio, which can be utilized to obtain transcriptions. Therefore, I instructed GPT-4 to use the control audio for this purpose:-
import os
import pandas as pd
import speech_recognition as sr
import time
def transcribe_wav(file_path, retries=3, timeout=10):
recognizer = sr.Recognizer()
with sr.AudioFile(file_path) as source:
audio = recognizer.record(source)
for i in range(retries):
try:
return recognizer.recognize_google(audio, language='en-US', show_all=False)
except sr.UnknownValueError:
print(f"Could not understand audio in {file_path}")
return ""
except sr.RequestError as e:
if i < retries - 1:
print(f"Request failed, retrying ({i + 1}/{retries})")
time.sleep(2 ** i)
else:
print(f"Could not request results from Google Speech Recognition service; {e}")
return ""
def save_progress(data, output_file="transcriptions.csv"):
header = not os.path.exists(output_file)
df = pd.DataFrame(data, columns=["file_name", "transcription"])
with open(output_file, 'a') as f:
df.to_csv(f, index=False, header=header)
def load_progress(input_file="transcriptions.csv"):
if os.path.exists(input_file):
df = pd.read_csv(input_file)
return df["file_name"].tolist()
else:
return []
control_folder = "control_train"
output_file = "transcriptions.csv"
output_data = []
processed_files = load_progress(output_file)
for file in os.listdir(control_folder):
fileWithoutExtension = os.path.splitext(file)[0]
if file.endswith(".wav") and fileWithoutExtension not in processed_files:
file_path = os.path.join(control_folder, file)
transcription = transcribe_wav(file_path)
if transcription == "":
continue
# remove .wav from file name
file = os.path.splitext(file)[0]
output_data.append((file, transcription))
save_progress(output_data, output_file)
print(f"Saved transcription for {file}")
Explanation: The code is transcribing audio files in WAV format in the control_train folder using the Google Speech Recognition service. It first defines a function called transcribe_wav takes in the file path of an audio file and uses the SpeechRecognition library to recognize the speech in the audio file using the Google Speech Recognition service. If the service fails to recognize the speech, the function retries up to three times before giving up. It then defines two helper functions called save_progress and load_progress that respectively saves and loads the progress of the transcription process to and from a CSV file. Finally, it loads the list of already processed files from the CSV file, loops through each audio file in the control_train folder that has not been processed yet, transcribes the speech in the audio file using the transcribe_wav function saves the transcription to the CSV file using the save_progress function, and prints a message indicating that the transcription has been saved.
The transcribed data is saved in a .csv file in the following format:-
| file_name | transcriptions |
| F02_B1_C11_M2 | trust |
| M03_UW13_C14_M6 | life |
| F03_B4_B1_M6 | command |
Final datasets prepared
Dysarthria training audio - This is a collection of various speakers and their pre-processed audio, following the cleaning process outlined earlier. There are approximately 15,000 samples in this category.
Dysarthria testing audio = This type of data differs from the above as it is not utilized in the training process. Instead, it is solely used to evaluate the accuracy of our trained model when introduced to unfamiliar data. With close to 5,000 samples falling into this category, it serves as a crucial component in evaluating the effectiveness of our model.
The
transcriptions.csvfile - This and the dysarthria training audio are in sync i.e. no transcriptions were generated from the control audio for the corresponding dysarthria testing audio.
The Model
When I presented the challenge of developing an ASR for identifying dysarthric speech to GPT-4, it recommended utilizing the Wav2vec2 model through Python code. As I encountered errors while running the code on certain data, I provided them to GPT-4, which eventually gave back the code that effectively handled unusual data lengths, shapes, and modulo operations.
Here is the code that involves training the model:-
import os
import re
import numpy as np
import pandas as pd
import torch
import torchaudio
from torch.utils.data import DataLoader, Dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from torch.optim.lr_scheduler import ReduceLROnPlateau
from sklearn.model_selection import train_test_split
from torch.nn.utils.rnn import pad_sequence
from transformers import get_linear_schedule_with_warmup
def normalize_waveform(waveform):
return waveform / torch.max(torch.abs(waveform))
def contains_nan(tensor):
return torch.isnan(tensor).any().item()
def calculate_validation_loss(validation_loader, model, device):
model.eval()
total_val_loss = 0
with torch.no_grad():
for batch in validation_loader:
input_values, labels = batch
input_values, labels = input_values.to(device), labels.to(device)
outputs = model(input_values, labels=labels)
loss = outputs.loss
total_val_loss += loss.item()
model.train()
return total_val_loss / len(validation_loader)
def custom_collate_fn(batch):
input_values, labels = zip(*batch)
# Remove the extra dimension from input values
input_values = [iv.squeeze(0) for iv in input_values]
labels = [l.squeeze(0) for l in labels]
# Filter out empty tensors
filtered_data = [(iv, l) for iv, l in zip(input_values, labels) if l.dim() != 0]
input_values, labels = zip(*filtered_data)
input_values = pad_sequence(input_values, batch_first=True)
labels = pad_sequence(labels, batch_first=True)
return input_values, labels
def get_last_part(filename):
base_name = os.path.splitext(os.path.basename(filename))[0]
if base_name[0] == 'C':
base_name = base_name[1:]
return base_name
def read_transcription_file(file_path):
with open(file_path, 'r') as f:
return f.read().strip()
class DysarthriaDataset(Dataset):
def __init__(self, audio_paths, transcriptions, processor):
self.audio_paths = audio_paths
self.transcriptions = transcriptions
self.processor = processor
def __len__(self):
return len(self.audio_paths)
def __getitem__(self, idx):
audio_path = self.audio_paths[idx]
transcription = self.transcriptions[idx]
# Load audio and preprocess
waveform, _ = torchaudio.load(audio_path)
waveform = normalize_waveform(waveform)
input_values = self.processor(waveform, return_tensors='pt', sampling_rate=16000).input_values[0]
# Process transcription
with self.processor.as_target_processor():
labels = self.processor(transcription, return_tensors='pt').input_ids[0]
return input_values, labels
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
processor.tokenizer.do_lower_case = True
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Replace with your actual file paths and transcriptions
# load audio paths and transcriptions
audio_dir = "/kaggle/input/dysarthric-audio/dysarthric_train_pre-processed/dysarthric_train_pre-processed"
# Load the CSV file into a DataFrame
csv_file = "/kaggle/input/dysarthric-audio/transcriptions.csv"
df = pd.read_csv(csv_file, nrows=1500)
# Extract the audio paths and transcriptions from the DataFrame
audio_paths = df['file_name'].apply(lambda x: os.path.join(audio_dir, x + '.wav')).tolist()
transcriptions = df['transcription'].tolist()
# Filter out audio-transcription pairs with empty transcriptions or missing audio files
non_empty_pairs = [(audio, text) for audio, text in zip(audio_paths, transcriptions) if text.strip() != '' and os.path.exists(audio)]
# Split the filtered pairs into separate lists of audio files and transcriptions
filtered_audio_files, filtered_transcriptions = zip(*non_empty_pairs)
train_audio_files, val_audio_files, train_transcriptions, val_transcriptions = train_test_split(
filtered_audio_files, filtered_transcriptions, test_size=0.1, random_state=42)
# Pass the filtered transcriptions to the DysarthriaDataset
train_dataset = DysarthriaDataset(train_audio_files, train_transcriptions, processor)
val_dataset = DysarthriaDataset(val_audio_files, val_transcriptions, processor)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, collate_fn=custom_collate_fn)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, collate_fn=custom_collate_fn)
epochs = 5
warmup_proportion = 0.1
num_training_steps = len(train_loader) * epochs
num_warmup_steps = int(warmup_proportion * num_training_steps)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-7)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps)
model.train()
for epoch in range(epochs):
epoch_loss = 0
for batch in train_loader:
input_values, labels = batch
input_values, labels = input_values.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(input_values, labels=labels)
loss = outputs.loss
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0)
optimizer.step()
scheduler.step();
epoch_loss += loss.item()
val_loss = calculate_validation_loss(val_loader, model, device)
print(f"Epoch {epoch + 1}/{epochs}, Train Loss: {epoch_loss / len(train_loader)}, Val Loss: {val_loss}")
model.save_pretrained("/kaggle/working/dysarthria_model_1")
processor.save_pretrained("/kaggle/working/dysarthria_model_1")
Explanation The code is a Python implementation of a Wav2Vec2 model used to build an ASR (Automatic Speech Recognition) tool for dysarthric people to transcribe the words spoken. The code is divided into several functions and classes that handle various tasks such as normalizing waveform, calculating validation loss, collating data, reading transcription files, and preparing datasets.
The processor and model is initialized with pre-trained weights from the Wav2Vec2 model. The DysarthriaDataset class is defined to load and preprocess the audio files and transcriptions.
The train_loader and val_loader are defined as DataLoader objects that load the train_dataset and val_dataset respectively. The train_loader and val_loader are used to train and validate the model respectively. The optimizer and scheduler is defined to optimize the model's parameters during training.
The model is trained for epochs number of epochs with each epoch having a num_training_steps number of training steps. The validation loss is calculated after each epoch. The model's parameters are saved after training.
That's a pretty nice explanation by Hashnode's writing assistant ✨.
The Training
It took some time to develop the code to its current state, working on it only during the last and current weekends. My focus was solely on instructing GPT-4 to solve errors in the code it generated, rather than brainstorming solutions. The shared dataset was not my initial starting point, as the original data lacked diversity and had low-quality transcriptions. To enhance the dataset's diversity, I prompted GPT-4 with additional information to split the data into training and testing sets while using a more robust library to improve transcription.
Initially, I used my laptop as my first training machine. I began with a sample size of 100, which later increased to 500. Unfortunately, I encountered strange results during training as the loss became "nan", and I felt I had hit a wall prematurely. However, the next day, I discovered that my code only read file names, not their content 🤦 . After fixing this issue, my losses produced numerical values.

I discussed this project with my friend with whom I collaborated back for the college project and he suggested to checkout Kaggle to get free powerful GPUs to train the model. I certainly needed to do that because at one time I tried training the model with 5k samples in my machine and after even 1.5 hours, the first epoch wasn't even logged 😅.
So I took my whole setup to Kaggle. This happened very early on in the process, so even on Kaggle, a lot of data that wasn't polished enough got uploaded only to end up with the polished one which I stated in the final datasets section above.
Kaggle allows you to use powerful GPUs with some user data confirmation. I used the GPU P100 on my friend's recommendation.
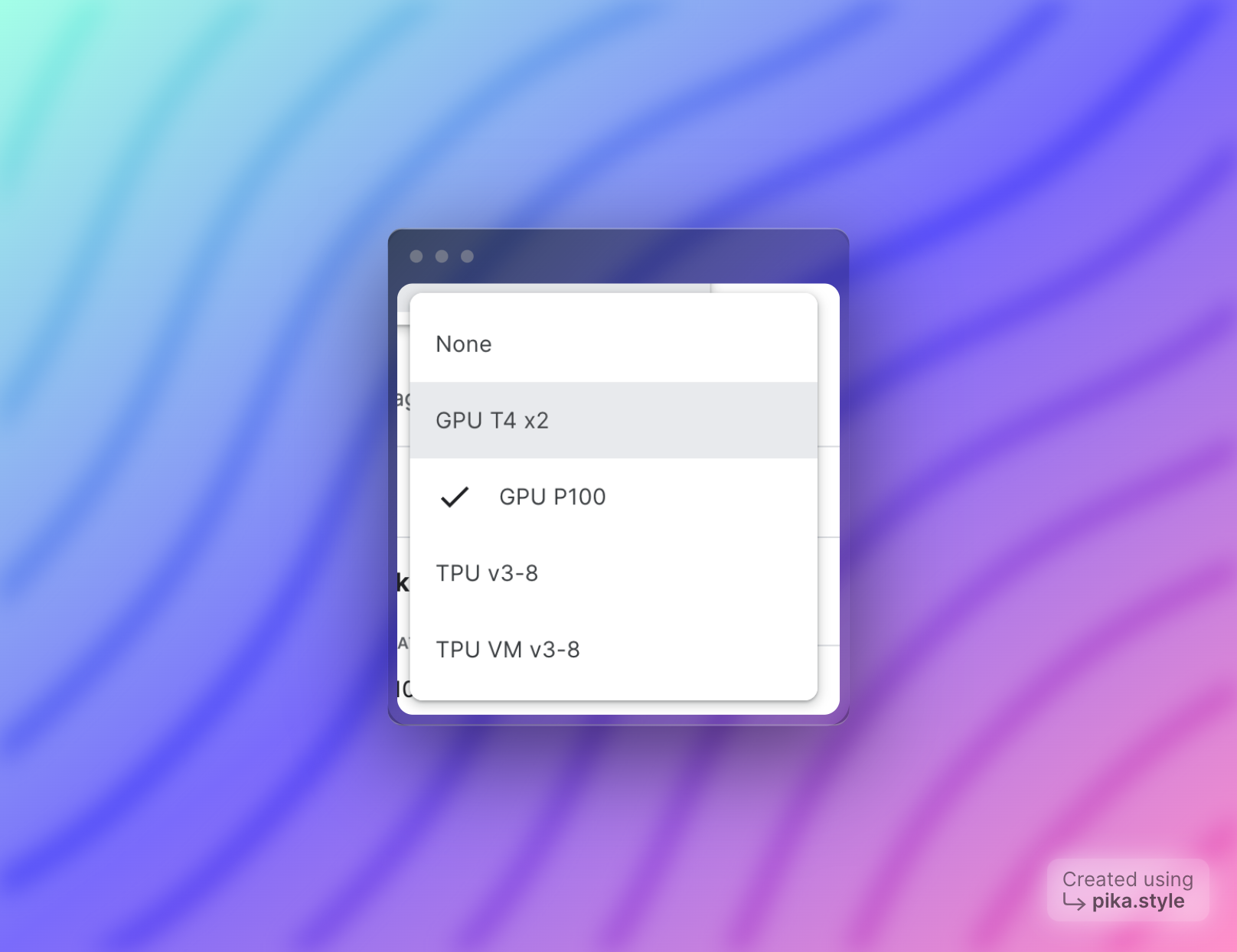
I began with a modest 100 samples, gradually increasing to 500, and found that training proceeded quickly. Thanks to Kaggle Playground, I could train 5,000 samples in just an hour.
To improve my results, I switched to the pre-trained facebook/wav2vec2-large-960h model. While I had initially used the facebook/wav2vec2-base-960h model, I found it struggled to handle larger sample sizes and often omitted poorly transcribed audio or empty strings in new audio samples.
The Results
As previously mentioned, my lack of domain expertise became a roadblock in my progress. This is not a new obstacle for me, as I faced similar challenges during my college days. However, I was curious to see how far GPT-4 could take me.

As I experimented with different no. of samples, I tested the trained model (which got saved in the training process) with different audio of dysarthric speakers. At one time, I thought that "Hey this might work" when I tested the following word:-
Command
Facebook one transcribed its dysarthric audio as "C MANG"
The trained one transcribed it as "COMA"
Initially, I believed this approach was effective. However, after testing the model with numerous input strings, I noticed a trend. It seemed that the model had learned to avoid having any gaps between transcribed letters. This could be due to my training the model solely on individual words rather than continuous speech.
Occasionally, the audio yields empty text or merely the first letters, despite the pre-trained model generating more letters appropriate but incorrect transcript.
I could only get the model to work with upto 2k samples. Anything more than that and the losses became negative/nan or the transcriptions worsened.
In certain scenarios, the trained model helped me to closely approximate the speech of dysarthric patients. For instance, if the patient spoke the word "INTO" with difficulty, the Facebook model produced "EN TOO" while the trained model generated "INTU". However, the output was not always consistent and I believe that modifying some parameters in GPT-4's instruction caused me to lose this capability after making some changes to my model.
There were instances of negative training and validation losses, indicating overfitting and a lack of learning in the model. This issue is exacerbated when more samples are being trained. To address this, I experimented with various factors such as learning rate, epochs, optimizers, and gradient normalization parameters. While reducing the epochs and learning rate resulted in non-negative values leaning toward 0, it also caused the model to transcribe inaccurately.
Upon questioning GPT-4 about my attempts, it recommended certain actions. However, I found it frustrating and unproductive as it failed to recall previous suggestions, resulting in a trial-and-error approach. Despite my repeated attempts to inform it of previous failures, I was met with the same unhelpful recommendations.

The Conclusion
Overall, I was attempting to make something work without the necessary domain knowledge. It became clear that GPT-4 can only be effective if the user has a good understanding of the subject matter they are utilizing it for.
This is where it shines:-
Unfortunately, I am facing a challenge where substantial research is required, and I lack knowledge not only about ASRs but also about the fundamental technology behind the Wav2vec2 model and the appropriate datasets required to solve my problem. Although I have a basic understanding of what I want, it is insufficient when dealing with a complex problem without an understanding of the limitations of the methods used to solve it.
Some doubts that crossed my mind:-
Is Wav2vec2 the right model selection to solve this issue?
How effective is a dataset comprising audio+transcription of single words in shaping and training a speech model, particularly one designed for continuous speech? Despite searching online for databases with continuous dysarthric speech, I couldn't find any good dataset. So, I downloaded a test file from the TORGO database, but it didn't work out. It only had single words or sometimes a sentence here and there, which didn't help me with what I was trying to do.
Have the input values for the model been appropriately transformed? Is the padding method for variable-length audio inputs satisfactory, or does it require adjustments?
The Desire
I'm still interested to find a solution to this problem, but with a knowledgeable person in the ML space who can handle the domain-specific shenanigans. I wanted to evaluate a model like Wav2vec2 only to set up a good enough pipeline to try this with Whisper since it was trained on much larger data and I expect it to do better.
I used replicate to try a sample of Dysarthric audio with Whisper 2.0 for the "Command" word and it transcribed it as "come on" (temperature - 0.2)and "COMMENT!" (temperature 0.4). That's way better than what wav2vec2 came up with.
If anyone is interested, there is a blog post to fine-tune Whisper for multi-lingual audio:-
I thought maybe if I get consistent and plausible results with Wav2vec2, I could go ahead with Whisper and make something much better. I am not even sure if Whisper is made for something like this but we won't know unless we try. If you're someone who wants to solve this problem and actually can make logical/intuitive decisions regarding the whole problem statement, reach out to me. That's how I would like to solve it further.

Achieving actual results would have been super cool, but I refuse to waste my time relying solely on luck. When building something, understanding the reasoning behind most of the decisions is crucial. It makes it easier to maintain and build stuff upon it later.
Thank you for your time 🙏